파일 특징
Linear -> 데이터가 저장될 때 DB와 같이 2차원 배열 형태가 아닌 1차원 배열 형태로 저장된다. 따라서 공격에 취약할 수 있다.
Byte addressable -> 바이트 단위로 읽는다.
프로세스간 공유 가능 -> 디스크에서 그냥 읽으면 됨
파일로 DB를 만들 수 있는가? -> 파일 바이트를 단위로 묶어서 예를들어 8바이트씩 레코드 1, 2, 3으로 지정하면 DB를 만들 수 있다.
그럼 파일이 있는데 DB는 필요없지 않는가? -> 은행에서 컴퓨터가 갑자기 꺼지면 파일 데이터가 날아갔다면?? -> 데이터를 보호하기 위해서 데이터베이스는 필요하다.
파일 시스템 역할
파일과 물리디스크 블록 간의 mapping을 제공
=============================
| File block number | Disk block number |
| 1 | 108 |
| 2 | 3010 |
| 3 | 3011 |
=============================
Metadata
Name -> 이름
Type -> 확장자
Location -> 디스크 블록 위치
Size -> 크기
Protection -> 권한
Metadata는 디스크에 저장됨. 따라서 inode에 위치한 메타데이터를 통해서 파일에 접근할 수 있다. 따라서 메타데이터와 실제 파일에 접근함으로써 2번의 접근이 발생하므로 Caching이 필요하다. 즉, 캐싱을 위해 메모리에도 Metadata가 있다.
Caching 문제점 -> 메모리의 Metadata와 디스크의 Metadata를 일정 시간마다 동기화하지만 그 사이에 컴퓨터에 문제가 생기면 컴퓨터를 재부팅할 때 디스크의 Metadata로 읽기 때문에 일관성이 없어질 수 있다.
File Operation
Open -> 디스크의 metadata를 메모리에 캐싱
Close -> 메모리에 저장된 metadata를 디스크로 저장
Mount 장점
Distributed FS로 확장 용이 -> Network file system(NFS)을 마운트하여 로컬 파일인 것 처럼 사용
Data block 저장위치 할당기법
Contiguous Allocation -> 파일을 물리적으로 연속된 disk block에 저장
Linked List Allocation -> 링크 리스트로 파일 데이터 저장 -> ex) MS_DOS의 FAT 파일 시스템
Linked List Allocation Using Index -> 파일 data block의 인덱스를 index block에 저장 -> 단점 : 최대 파일의 크기가 고정됨
inode -> 파일에 대한 data block index를 계층 형태로 관리하는 방법
inode 내부에는 direct blocks, single indirect, double indirect가 있는데 파일이 작으면 direct blocks을 사용하고 파일이 커지면 sigle indirect, 더 커지면 double indirect를 사용한다.
inode 용량
가정
Block Size -> 4KB
Direct Block 개수 -> 12
Pointer Size -> 4B
Direct Block -> 4KB x 12 = 48KB
Indirect Block 1개 -> 4KB x 1024 -> 4MB // (1024 = 4B(포인터 크기))
만약 파일을 읽을 때 SSD가 RAM 만큼 속도가 빠르다면 디렉토리 캐싱이 필요할까??
-> 아무리 SSD가 메모리 만큼 빠르다 하더라도 만약 a/b/c 같은 디렉토리에 접근하기 위해서 디스크에 최소 6번 이상 접근해야하므로 캐싱을 하는 것이 더 효울적이다.
On-disk structure
-> Disk에 저장되어 있는 자료 구조
Boot block -> 디스크의 첫번째 block으로 운영체제가 시작하기 위해 필요한 정보를 가지고 있는 block
Super block -> 파일 시스템 관련 정보들이 어디에 저장되어 있는지에 대한 메타 데이터. 중요하기 때문에 중복해서 저장. inode table의 위치 저장.
File control block (FCB) -> 리눅스에서는 inode로 구현됨

Buffer Cache
- 정의: 최근에 사용된 disk block을 메모리 공간에 caching
Motivation
- Disk I/O의 시간이 메모리 접근 시간보다 매우 큼
- Disk block의 접근 패턴에도 locality가 있음
특징
- Virtual Memory와 달리 MMU와 같은 H/W의 지원을 받지 않음
- Read와 write의 연산 수행의 결과와 실제 disk의 내용은 asynchronous함
ex) 워드로 문서작업을 할 때 컴퓨터가 꺼지면 자료가 날아감. 만약 저장 버튼을 누르면 flush가 일어나서 디스크에 저장됨
Read System Call
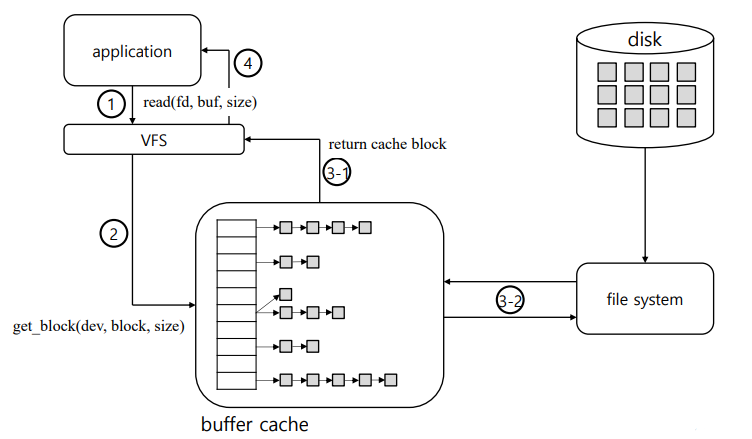
진행 순서
1. Application에서 read(fd, buf, size)를 호출
2. VFS에서는 read에서 전달 받은 인자를 통해 data의 위치 정보인 장 치(dev), block 번호, size로 바꾸어 buffer cache에 해당하는 block 이 있는지 찾음
3-1. buffer cache에 이미 cache된 block이 있으면 VFS에게 반환한다.
3-2. 요청한 block이 cache에 없으면 file system에게 block을 요청하 고 그 block을 자신의 cache entry에 추가 3-1의 과정을 수행
4. VFS는 application에서 인자로 넘겨준 buf에 읽어온 block 들을 copy하고 읽어온 byte수를 return
write System Call
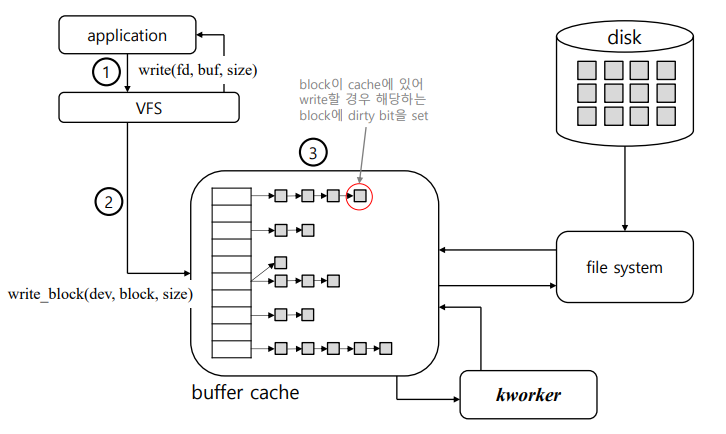
진행 순서
1. Application에서 write (fd, buf, size)를 호출
2. VFS는 write 인자로 받은 fd, buf, size를 통해서 dev, block, size로 변환하여 buffer cache의 block에 write를 수행 이때 사용하고자 하는 block이 buffer cache에 없다면, read system call 처럼 사용하고자 하는 block을 먼저 disk에서 가져옴
3. kworker 가 write를 수행한 block에 대해서 dirty bit을 체크하여 변 한 내용이 disk에 반영될 수 있도록 함
kworker
-> Buffer cache의 내용과 disk block의 동기화를 수행하는 kernel thread
-> Buffer cache의 entry중 dirty bit이 체크 되어 있는 block들을 disk 에 저장
-> 주기적(data: 30초, metadata: 5초)으로 동작하며 block이 cache에 머문 시간, dirty bit 체크와 같은 조건에 따라서 동작
-> Application에서 fsync(2) system call을 호출하면 kworker는 강제적 으로 buffer cache의 내용을 disk에 반영
LFS(Log Structured File System)
Idea -> 기존에는 metadata가 나누어져 있어서 여러개의 small write가 수행됬지만 효율이 떨어지므로 small write를 묶에서 sequentially하게 사용하면 속도가 빨라지지 않을까하는 생각에서 출발 -> seek을 최소화할 수 있다.
-> 원래 디스크 기반 파일시스템으로 제안되었으나 플래시 파일 시스템의 기반이 됨
ex) data block, data inode, directory, directory inode를 따로 write 하지말고 묶어서 한꺼번에 write

Read Indexing
-> 기존의 리눅스 파일 시스템에서는 inode가 고정되어있고 superblock에서 해당 위치를 찾을 수 있었지만 LFS에서는 데이터를 write 할때마다 해당 inode는 추가로 append되므로 inode가 여러개가 된다. 따라서 inode map이라는 중간 계층을 도입해서 가장 최신의 inode 위치를 inode map에 저장하므로 inode 위치를 알 수 있다.
Crash recovery -> 기존의 파일 시스템은 디스크 전체를 다시 검사해야하지만 LFS는 제일 나중에 쓴 부분만 보면 된다.
ex) Linux 파일 시스템과 Log-structured file system에서 전원이 나갔다가 다시 들어왔다고 가정
Linux 파일 시스템에서는 파일의 메타데이터를 가지고 있는 inode는 inode table block에 저장되고 데이터 블록은 데이터 블록 영역에 따로 따로 저장된다. 저장된 데이터 블록은 inode를 통해 접근할 수 있다. 파일의 metadata는 synchronous하게 업데이트가 되지만, data는 asynchronous하게 업데이트되기 때문에, metadata와 data를 비교하여 consistency를 체크할 수 있다. Log structured File System(LFS)는 수정사항이 발생 했을 때, 그 수정사항을 rewrite하지 않고 sequentially하게 모두 디스크에 쓴다. 기존에 consistency를 체크하기 위해서는 모든 디스크를 스캔해야 했지만, LFS에서는 파일의 뒤에 있는 정보만 확인하면 된다.
기존 리눅스 파일 시스템

LFS 파일 시스템

Free space management -> Free space를 가능한 크게 유지하는 것
Threading: 뜨개질하듯이 엮는 것
Copying: live 데이터를 옮기는 것

Container
컨테이너란? -> Process with “constraints” for isolation -> 제약이 걸려있는 분리된 프로세스
Resource constraints: cgroup
$cat /proc/PID/cgroup (CPU, memory) -> CPU와 메모리의 한계를 정함
Security constraints: seccomp profiles
Filter (block) system calls -> 위험한 시스템콜은 허락안함
Container runtime이 위 제약들을 컨트롤한다.
Namespaces -> 네임스페이스 기준으로 분리됨 -> 즉, 같은 커널 위에서 자신만의 rootfs를 가진 Namespace안에서만 동작한다. 자기 자신만의 공간을 만든다고 볼 수 있다.
DKI(Driver Kernel Interface)
-> 다양한 I/O 장치들을 일관되게 다루기 위한 Kernel과 Driver 사이의 Interface
-> 어플리케이션이 디바이스의 종류에 무관하게 파일에 접근 가능
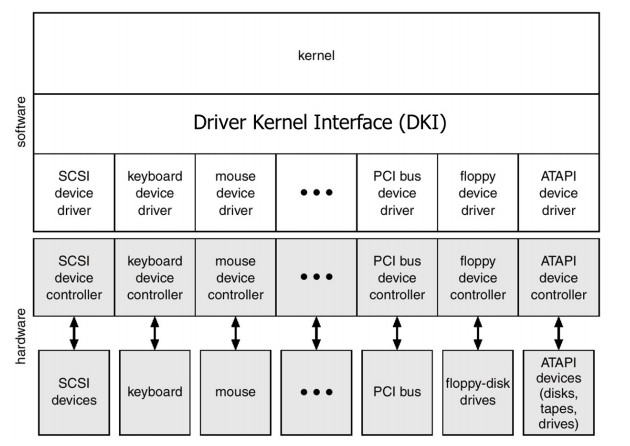
Driver Kernel Interface 설계
1. Device as file -> /dev/tty0 -> 장치가 연결되면 tty0 디렉토리에 파일 형식으로 불러옴
2. Layering
-> device와 driver를 구분하여 역할을 명확히 함
device -> device 내의 firmware. 하드웨어 제조사가 정의하여 직접 하드웨어를 제어하는 프로그램. Device driver 가 이를 이용하여 장치를 제어
driver -> 커널 모듈로 삽입되는 device driver. 삽입될 OS의 DKI가 정의하는 동작들을 device에 맞춰 구현.
Divice 동작 방식
Character Device
-> Unbuffered access –> 파일 시스템 지원없이 접근 -> 예를 들어 키보드는 바로바로 장치에 접근할 수 있어야하므로 한 바이트씩 동작하는 Character Device를 사용함
Block Device
-> Buffered access -> 고정 길이 단위의 입출력(block) –> 대표적인 장치는 disk이며 file system이 block device에 대한 입출력을 담당
'잡동사니' 카테고리의 다른 글
| 심플한 원격 데스크톱 (0) | 2021.09.29 |
|---|---|
| 외부에서 접속 가능한 나만의 서버 만들기 (0) | 2021.09.29 |
| [디지털 포렌식 개념] (0) | 2021.09.17 |
| [데이터베이스 개념] (0) | 2021.09.17 |
| 북마크로 유튜브 광고 스킵하기 (0) | 2021.09.16 |




댓글