데이터 정의어 DDL(Data Definition Language) -> 새로운 데이터베이스를 구축하기 위해 스키마 정의 또는 기존 스키마 삭제 또는 수정. 생성된 스키마는 데이터 사전에 저장됨
데이터 조작어 DML(Data Manipulation Language) -> 사용자가 데이터의 삽입, 삭제, 수정, 검색 등의 처리를 DBMS에 요구하기 위해 사용하는 언어
관계 데이터 모델
관계 데이터 모델은 릴레이션에 데이터를 담아서 데이터베이스에 저장한다. 예를 들어 아래와 같이 고객 릴레이션이 있다고 가정하자. 행은 투플을 나타내고 열은 속성을 나타낸다. 스키마는 {고객아이디, 고객이름, 나이, 등급 , 직업, 적립금} 구조를 의미하고 인스턴스는 속성을 제외한 고객 데이터들을 의미한다.
속성 속성
↓ ↓
====================================================================
| 고객아이디 | 고객이름 | 나이 | 등급 | 직업 | 적립금 |
도메인-> | CHAR(20) | CHAR(20) | INT | CHAR(10) | CHAR(10) | INT |
|-------------------------------------------------------------------------------------------------------------------|
투플 -> | apple | 김현준 | 20 | gold | 학생 | 1000 |
|-------------------------------------------------------------------------------------------------------------------|
| banana | 정소화 | 25 | vip | 간호사 | 2500 |
====================================================================
슈퍼키(Super key) -> 유일성의 특성을 만족하는 속성 또는 속성들의 집합이다. 슈퍼키에서 키 값이 같은 투플은 존재할 수 없다. 예를 들어 고객아이디는 유일하므로 조건을 만족시킬 수 있으나 나머지 속성들은 같은 이름, 같은 나이 등등 조건을 만족시키지 못한다. 하지만 고객아이디를 포함한 집합들은 고객아이디가 유일하므로 모두 슈퍼키에 포함된다. ex) {고객아이디, 고객이름, 적립금} 집합은 슈퍼키가 될 수 있다.
후보키(Candidate key) -> 유일성과 최소성을 만족하는 속성 또는 속성들의 집합이다.
기본키(Primary key) -> 후보키 중에서 적절하게 고르면 된다.
외래키(Foreign key) -> 어떤 릴레이션에 소속된 속성 또는 속성 집합이 다른 릴레이션의 기본키가 되는 키를 의미한다. 다른 릴레이션의 키를 참조하므로 데이터에 오류가 발생할 경우 바로 알 수 있다.
관계 대수
Six basic operators
select: σ => 조건 만족하는 투플 반환
project: π => 주어진 속성들의 값으로만 구성된 투플 반환
union: ∪ => 합집합
set intersection ∩ => 교집합
set difference: – => 차집합
Cartesian product: x => 릴레이션 R, S 각 투플을 모두 연결하여 만들어진 새로운 투플 반환
Join -> select와 Cartesian product를 합한거
Assignment -> 위 표현 조합에 별칭
Consider the following relational schema (예제)
branch (branch-name, branch-city, assets)
account (account-number, branch-name, balance)
depositor (customer-name, account-number)
customer (customer-name, customer-street, customer-city)
loan (loan-number, branch-name, amount)
borrower (customer-name, loan-number)
Make relational expressions for the following questions
1. Find the loan number for each loan of an amount greater than $1200

2. Find the names of all customers who have a loan, an account, or both, from the bank

3. Find the names of all customers who have a loan at the Perryidge branch

loan 테이블에 은행명은 있지만 소비자 이름이 없으므로 Cartesian-Product로 borrower테이블과 loan 테이블을 합친 후 그 중에 loan_number만 같은 경우를 추출합니다. 다음으로 그 중에서 은행명이 Perryidge인 투플을 추출하고 소비자 이름 속성 값들을 출력합니다.
4. Find the names of all customers who have a loan at the Perryidge branch but do not have an account at any branch of the bank

3번에서 예금자들의 이름만 빼면 된다.
Find the largest account balance

account 테이블을 자기 자신과 카티전 곱을 하고 가장 큰 Balance를 제외한 나머지를 빼주면 가장 큰 계좌 잔액을 조회할 수 있다.
Creat Table 예시
create table course (
course_id varchar(8),
title varchar(50),
dept_name varchar(20),
credits numeric(2,0),
primary key (course_id),
foreign key (dept_name) references department) ;
Insert Table 예시
insert into instructor values ('10211', 'Smith', 'Biology', 66000) ;
Alter Table 예시
alter table r add A D ;
r -> table A -> attribute D -> Domain
alter table r drop A
-> r 테이블에서 A 속성 제거
Select
중복을 제거할때 -> select distinct dept_name from instructor;
중복을 유지할때 -> select all dept_name from instructor;
Cartesian product -> select * from instructor, teaches ;
like
dar을 포함하고 있는 이름 -> select name from instructor where name like '%dar%’ ;
최소 3글자 이상 -> '_ _ _%'
Order
name 속성에서 알파벳 순서대로 나열 -> select distinct name from instructor order by name ;
between -> select name from instructor where salary between 90000 and 100000 ;
Tuple comparision -> select name, course_id from instructor, teaches where (instructor.ID, dept_name) = (teaches.ID, 'Biology');
Set Operation(집합 연산자)
Find courses that ran in Fall 2017 or in Spring 2018
(select course_id from section where sem = 'Fall' and year = 2017)
union
(select course_id from section where sem = 'Spring' and year = 2018) ;
Find courses that ran in Fall 2017 and in Spring 2018
(select course_id from section where sem = 'Fall' and year = 2017)
intersect
(select course_id from section where sem = 'Spring' and year = 2018) ;
Find courses that ran in Fall 2017 but not in Spring 2018
(select course_id from section where sem = 'Fall' and year = 2017)
except
(select course_id from section where sem = 'Spring' and year = 2018) ;
중복유지 -> union all, intersect all, except all
집계 함수(Aggregate Functions)
-> 여러 행으로부터 하나의 결과값을 반환하는 함수
avg: average value
min: minimum value
max: maximum value
sum: sum of values
count: number of values
ex-> select avg (salary) from instructor where dept_name= 'Comp. Sci.';
Group By
Find the average salary of instructors in each department
-> select dept_name, avg (salary) as avg_salary from instructor group by dept_name;
Having Clause
select dept_name, avg (salary) as avg_salary
from instructor
group by dept_name
having avg (salary) > 42000;
In
-> in: 하나라도 참이면 True <-> not in : 모두 거짓이면 True
Find courses offered in Fall 2017 and in Spring 2018 ->
select distinct course_id
from section
where semester = 'Fall' and year= 2017 and course_id in (select course_id from section where semester = 'Spring' and year= 2018);
Some
-> some: 하나라도 참이면 True <-> not some: 하나라도 거짓이면 True
select name from instructor
where salary > some (select salary from instructor where dept name = 'Biology');
all
-> 모두 참이면 True <-> not all: 모두 거짓이면 True
select name
from instructor
where salary > all (select salary from instructor where dept name = 'Biology');
with
-> 일시적인 릴레이셔 정의
Find all departments where the total salary is greater than the average of the total salary at all departments
with dept _total (dept_name, value) as
(select dept_name, sum(salary)
from instructor
group by dept_name),
dept_total_avg(value) as
(select avg(value)
from dept_total)
select dept_name
from dept_total, dept_total_avg
where dept_total.value > dept_total_avg.value;
Delete
delete from instructor
where dept_name= 'Finance’ ;
Insertion
insert into course values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
update
update instructor
set salary = salary * 1.05
where salary < 70000;
Case
update instructor
set salary = case
when salary <= 100000 then salary * 1.05
else salary * 1.03
end ;
Join
Join의 종류
-> Natural join
-> Inner join
-> Outer join
Natural join
-> 두 테이블의 이름이 같은 속성들을 묶어서 결과를 나타내는 join
예시)
select name, course_id
from students, takes
where student.ID = takes.ID;
select name, course_id
from student natural join takes;
주의할 점
-> 이름이 같더라도 데이터 타입이 다르면 안된다.
아래 두 테이블이 있다고 가정하자.

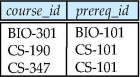
Inner join
-> 일반적인 join
Join 조건문
select * from student join takes on student_ID = takes_ID -> on의미: 양쪽의 속성을 지정할 수 있음 -> 중복 제거 X
select * from student join takes using ID -> using의미: ID 속성을 사용하여 join -> 중복 제거
-> Natural join과는 다르게 두 속성 모두 출력된다. 데이터가 일치하지 않으면 해당 데이터는 출력되지 않는다.
ex) course inner join prereq on course_id = prereq.course.id

Outer join 종류
Left outer join
-> 왼쪽 속성만 표시하고 일치하는 값이 없으면 null로 표시
ex) course left outer join prereq on course.course_id = prereq.course_id

Right outer join
-> left outer join과 반대
ex) couse natural right outer join prereq

Full outer join
-> 양쪽 모두 출력
ex) course full outer join prereq using (course_id)

View
보이고 싶은 속성들만 보여주는 기능
ex) A view of instructors without their salary
create view faculty as
select ID, name, dept_name
from instructor ;
Find all instructors in the Biology department
select name
from faculty
where dept_name = 'Biology’ ;
Transaction
-> 하나의 작업 단위
commit이 되면 트랜젝션이 완료되고 Rollback이 되면 작업하던 트랜젝션을 없었던일로 한다.
Constraint
not null -> null이 있으면 안됨
ex) name varchar(20) not null
unique (a,b,c,d)
ex) a, b, c, d 테이블 사이에 중복이 없어야한다.
primary key
check (P)
ex)
create table section
(course_id varchar (8),
sec_id varchar (8),
semester varchar (6),
year numeric (4,0),
building varchar (15),
room_number varchar (7),
time slot id varchar (4),
primary key (course_id, sec_id, semester, year),
check (semester in ('Fall', 'Winter', 'Spring', 'Summer’))) ;
Referential Integrity
cascade
-> 레퍼런싱 하는 튜플이 사라지거나 업데이트되면 같이 삭제하고 업데이트한다.
create table course (
(…
dept_name varchar(20),
foreign key (dept_name) references department
on delete cascade
on update cascade,
. . .) ;
set null -> 같이 삭제하지 않고 해당 값만 null로 변경
set default -> default 값을 미리 설정해놓으면 삭제될 경우 해당 값으로 변경
Authorization
grant
-> 권한 부여
사용법 : grant <privilege list> on <relation or view> to <user list>;
ex) grant select on department to Amit, Satoshi;
revoke
-> 권한 회수
사용법: revoke <privilege list> on <relation or view> from <user list>;
role
-> 사용자그룹
create a role <name>
옵션
with grant options -> 권한을 다른 사람에게 줄 수 있는 권한도 줌
ex) grant select on department to Amit with grant option;
cascade 옵션
ex) revoke select on department from Amit, Satoshi cascade;
-> 예를 들어 Amit이 Satoshi한테 권한을 주고 이후 관리자가 Amit의 권한을 회수했을 때 cascade 옵션으로 인해 Satoshi의 권한도 같이 사라진다.
restrict 옵션
revoke select on department from Amit, Satoshi restrict;
-> Amit의 권한을 뺏으려고 할 때 Amit이 권한을 준 사람들이 남아있다면 Amit의 권한을 회수할 수 없다.
'잡동사니' 카테고리의 다른 글
| [파일 시스템 개념] (0) | 2021.09.18 |
|---|---|
| [디지털 포렌식 개념] (0) | 2021.09.17 |
| 북마크로 유튜브 광고 스킵하기 (0) | 2021.09.16 |
| 티스토리 블로그 이미지 삽입 (0) | 2021.09.05 |
| [클라우드 컴퓨팅 개념] (0) | 2021.09.01 |



댓글