주문 조회 V1: 엔티티 직접 노출
Merge pull request #8 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@9bd8afa
ManyToOne Direct Exposure Entity
github.com
주문내역에서 추가로 주문한 상품 정보를 추가로 조회 -> (OneToMany)를 조회
Order 기준으로 컬렉션인 OrderItem 와 Item 이 필요하므로 LAZY를 추가로 초기화
주문 조회 V2: 엔티티를 Dto로 변환
Merge pull request #9 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@2d6a432
ManyToOne Entity Convert To DTO
github.com
배운 것
1. Order에 대해서 Dto를 만들면 OrderItems는 엔티티가 직접 노출되므로 OrderItems도 Dto를 만들어준다.
주문 조회 V3: 엔티티를 Dto로 변환 - 페치 조인 최적화
Merge pull request #10 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@d79fbdb
ManyToOne Fetch Join Optimization
github.com
배운 것
1. 주문이 2개이고 주문 당 orderItem이 2개인 경우 join 쿼리를 실행하면 DB에서는 orderItem 기준으로 4개의 데이터가 출력된다. 여기에 distinct를 추가한 경우 DB에서는 완전히 동일한 데이터가 아니므로 중복제거를 못해서 데이터가 4개로 출력되지만 JPA에서 자체적으로 pk가 같은 경우 중복을 제거하므로 2개가 출력된다.
단점:
1. 페이징 불가능
-> 원인: 일대다에서 일(1)을 기준으로 페이징 하고 싶은데 데이터는 다(N)를 기준으로 row가 생성된다.
-> 결과: 하이버네이트는 경고 로그를 남기고 모든 DB 데이터를 읽어서 메모리에서 페이징을 시도한다. 최악의 경우 장애로 이어질 수 있다.
2. 컬렉션 페치 조인은 1개만 사용할 수 있다.
주문 조회 V3: 엔티티를 Dto로 변환 - 페이징과 한계 돌파
Merge pull request #11 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@ea90f29
ManyToOne Paging And Break The Limit
github.com
배운 것
한계 돌파 방법
1. ToOne 관계를 모두 페치조인 한다. ToOne 관계는 row 수를 증가시키지 않으므로
2. 컬렉션은 지연 로딩으로 조회한다.
3. 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_size , @BatchSize 를 적용한다.
hibernate.default_batch_fetch_size: 글로벌 설정
@BatchSize: 개별 최적화
-> 이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.
hibernate.default_batch_fetch_size를 사용하면 size 만큼 in 쿼리를 사용해서 사용할 데이터를 미리 가져온다. 원래 2개의 주문으로 orderItems와 item을 가져오면 1+2+2로 5번의 쿼리가 실행되지만 hibernate.default_batch_fetch_size를 사용해서 1+1+1로 3번의 쿼리가 실행된다.
쿼리의 양은 3번으로 페치조인으로 1번에 모든 데이터를 가져오는 쿼리에 비해 늘었지만 쿼리 각각의 데이터 양은 최적화되어서 네트워크에서 전송해야하는 데이터 양이 줄어드므로 오히려 성능이 향상될 수도 있다.
사이즈는 100~1000개가 적당하다. 서버가 버틸 수 있으면 늘려도 된다.
결론
ToOne 관계는 페치 조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이는 방식을 사용하고 나머지는 hibernate.default_batch_fetch_size로 최적화하자.
주문 조회 V4: JPA에서 DTO 직접 조회
Merge pull request #12 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@b228742
ManyToOne Directly Inquire From JPA To DTO
github.com
배운 것
order, member, delivery를 가져오는데 쿼리 한번, orderitems, item을 한꺼번에 가져오지만 order가 2개이므로 2번 호출되므로 1 + 2 로 총 3번의 쿼리가 호출된다.
처음 쿼리의 결과로 2개의 데이터 N을 가져오고 N만큼의 쿼리가 추가로 발생하므로 결과적으로 N+1 문제가 생긴다.
주문 조회 V5: JPA에서 DTO 직접 조회 - 컬렉션 조회 최적화
Merge pull request #13 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@72498f1
ManyToOne Directly Inquire From JPA To DTO_Collection Inquire Optimiz…
github.com
배운 것
1. 이전에는 order마다 ordeitems와 item을 불러오므로 2개의 주문을 하면 1+2로 N+1 문제가 발생했지만 해당 예제에서는 order을 in 문법을 이용해서 한번에 불러오므로 2개의 주문을 하면 2번의 쿼리가 발생한다.
-> 루트 1번 컬렉션 1번으로 총 2번의 쿼리 호출
2. Dto를 Map 형태로 변환해서 메모리에 저장할 수 있다.
주문 조회 V6: JPA에서 DTO 직접 조회 - 플랫 데이터 최적화
Merge pull request #14 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@9291afc
ManyToOne Directly Inquire From JPA To DTO, Flat Data Optimization
github.com
배운 것
1. 장점 -> query 1번, 단점 ->페이징 안됨
API 개발 고급 정리
정리
엔티티 조회
엔티티를 조회해서 그대로 반환: V1
엔티티 조회 후 DTO로 변환: V2
페치 조인으로 쿼리 수 최적화: V3
컬렉션 페이징과 한계 돌파: V3.1
컬렉션은 페치 조인시 페이징이 불가능 ToOne 관계는 페치 조인으로 쿼리 수 최적화
컬렉션은 페치 조인 대신에 지연 로딩을 유지하고, hibernate.default_batch_fetch_size , @BatchSize 로 최적화
DTO 직접 조회
JPA에서 DTO를 직접 조회: V4
컬렉션 조회 최적화 - 일대다 관계인 컬렉션은 IN 절을 활용해서 메모리에 미리 조회해서 최적화: V5
플랫 데이터 최적화 - JOIN 결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환: V6
권장 순서
1. 엔티티 조회 방식으로 우선 접근
1. 페치조인으로 쿼리 수를 최적화
2. 컬렉션 최적화
1. 페이징 필요 hibernate.default_batch_fetch_size , @BatchSize 로 최적화
2. 페이징 필요X 페치 조인 사용
2. 엔티티 조회 방식으로 해결이 안되면 DTO 조회 방식 사용
3. DTO 조회 방식으로 해결이 안되면 NativeSQL or 스프링 JdbcTemplate
OSVI와 성능 최적화
Merge pull request #15 from Lemon-soju/slave-01 · Lemon-soju/Spring-Boot-and-JPA-toddler-practice-02@6204288
OSVI And Performance Optimization
github.com
OSIV ON
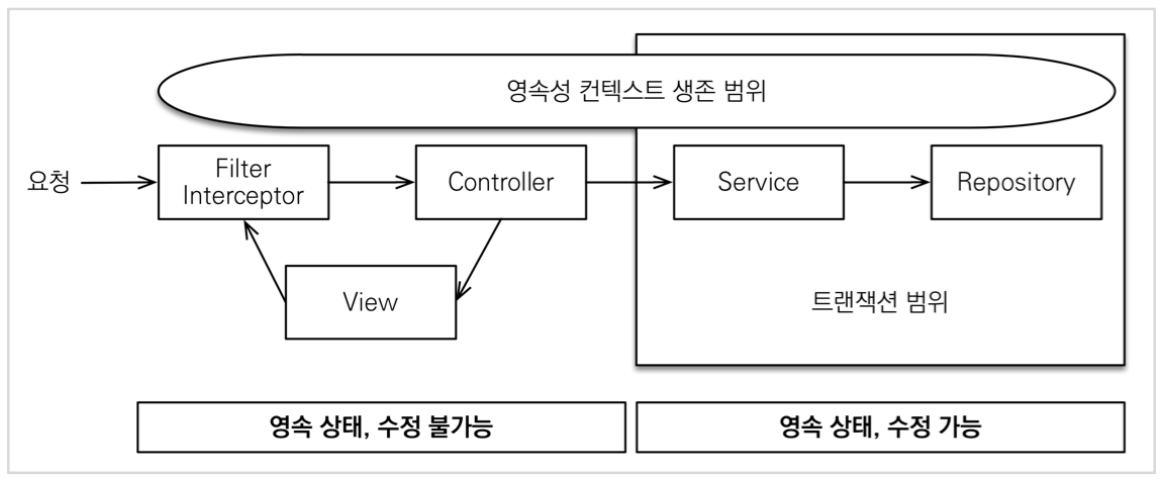
spring.jpa.open-in-view : true 기본값
이 기본값을 뿌리면서 애플리케이션 시작 시점에 warn 로그를 남기는 것은 이유가 있다.
OSIV 전략은 트랜잭션 시작처럼 최초 데이터베이스 커넥션 시작 시점부터 API 응답이 끝날 때 까지 영속성 컨텍스트와 데이터베이스 커넥션을 유지한다. 그래서 지금까지 View Template이나 API 컨트롤러에서 지연 로딩이 가능했던 것이다. 지연 로딩은 영속성 컨텍스트가 살아있어야 가능하고, 영속성 컨텍스트는 기본적으로 데이터베이스 커넥션을 유지한다. 이것 자체가 큰 장점이다.
그런데 이 전략은 너무 오랜시간동안 데이터베이스 커넥션 리소스를 사용하기 때문에, 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자랄 수 있다. 이것은 결국 장애로 이어진다. 예를 들어서 컨트롤러에서 외부 API를 호출하면 외부 API 대기 시간 만큼 커넥션 리소스를 반환하지 못하고, 유지해야 한다.
OSIV OFF

spring.jpa.open-in-view: false OSIV 종료
OSIV를 끄면 트랜잭션을 종료할 때 영속성 컨텍스트를 닫고, 데이터베이스 커넥션도 반환한다. 따라서 커넥션 리소스를 낭비하지 않는다.
OSIV를 끄면 모든 지연로딩을 트랜잭션 안에서 처리해야 한다. 따라서 지금까지 작성한 많은 지연 로딩 코드를 트랜잭션 안으로 넣어야 하는 단점이 있다. 그리고 view template에서 지연로딩이 동작하지 않는다. 결론적으로 트랜잭션이 끝나기 전에 지연 로딩을 강제로 호출해 두어야 한다.
커멘드와 쿼리 분리
실무에서 OSIV를 끈 상태로 복잡성을 관리하는 좋은 방법이 있다. 바로 Command와 Query를 분리하는 것이다.
보통 비즈니스 로직은 특정 엔티티 몇게를 등록하거나 수정하는 것이므로 성능이 크게 문제가 되지 않는다. 그런데 복잡한 화면을 출력하기 위한 쿼리는 화면에 맞추어 성능을 최적화 하는 것이 중요하다. 하지만 그 복잡성에 비해 핵심 비즈니스에 큰 영향을 주는 것은 아니다. 그래서 크고 복잡한 애플리케이션을 개발한다면, 이 둘의 관심사를 명확하게 분리하는 선택은 유지보수 관점에서 충분히 의미 있다. 단순하게 설명해서 다음처럼 분리하는 것이다.
OrderService
OrderService: 핵심 비즈니스 로직
OrderQueryService: 화면이나 API에 맞춘 서비스 (주로 읽기 전용 트랜잭션 사용)
보통 서비스 계층에서 트랜잭션을 유지한다. 두 서비스 모두 트랜잭션을 유지하면서 지연 로딩을 사용할 수 있다.
참고: 고객 서비스의 실시간 API는 OSIV를 끄고, ADMIN 처럼 커넥션을 많이 사용하지 않는 곳에서는 OSIV를 키는 것이 좋다.
'웹 개발 > Back End' 카테고리의 다른 글
| 스프링 개념 정리(1) (0) | 2022.08.27 |
|---|---|
| 실전! 스프링 부트와 JPA 활용2 - 스프링 데이터 JPA, QueryDSL 소개 (0) | 2022.01.28 |
| 실전! 스프링 부트와 JPA 활용2 - API 개발 고급 - 지연 로딩과 조회 성능 최적화 (0) | 2022.01.25 |
| 실전! 스프링 부트와 JPA 활용2 - API 개발 기본 (0) | 2022.01.25 |
| 실전! 스프링 부트와 JPA 활용1 - 웹 계층 개발 (0) | 2022.01.09 |
댓글